fuzzytree.FuzzyDecisionTreeClassifier¶
- class fuzzytree.FuzzyDecisionTreeClassifier(fuzziness=0.8, criterion='gini', max_depth=None, min_membership_split=2.0, min_membership_leaf=1.0, min_impurity_decrease=0.0)[source]¶
A fuzzy decision tree classifier. Read more in the User Guide.
- Parameters:
- fuzzinessfloat, default=0.8
The fuzziness parameter that controls softness of the tree between 0. (hard) and 1. (soft).
- criterion{“gini”, “entropy”, “misclassification”}, default=”gini”
The function to measure the quality of a split. Supported criteria are “gini” for the Gini impurity, “entropy” for the information gain and “misclassification” for the misclassification ratio.
- max_depthint, default=None
The maximum depth of the tree. If None, then nodes are expanded until all leaves are pure or until all leaves contain less than min_membership_split sum of membership or recursion limit is met.
- min_membership_splitfloat, default=2.0
The minimum sum of membership required to split an internal node.
- min_membership_leaffloat, default=1.0
The minimum sum of membership required to be at a leaf node. A split point at any depth will only be considered if it leaves at least
min_membership_leafsum of membership in each of the left and right branches. This may have the effect of smoothing the model, especially in regression.- min_impurity_decreasefloat, default=0.0
A node will be split if this split induces a decrease of the impurity greater than or equal to this value.
The weighted impurity decrease equation is the following:
impurity - M_t_R / M_t * right_impurity - M_t_L / M_t * left_impurity
where
M_t_Lis the sum of membership in the left child andM_t_Ris the sum of membership in the right child.
- Attributes:
- classes_ndarray of shape (n_classes,)
The classes labels.
- n_classes_int or list of int
The number of classes (for single output problems), or a list containing the number of classes for each output (for multi-output problems).
- n_features_int
The number of features when
fitis performed.- n_outputs_int
The number of outputs when
fitis performed. Currently, always equals 1.- tree_FuzzyTree
The underlying Tree object. Please refer to
help(fuzzytree._fuzzy_tree.FuzzyTree)for attributes of Tree object and for basic usage of these attributes.
Notes
The default values for the parameters controlling the size of the trees (e.g.
max_depth,min_membership_leaf, etc.) lead to fully grown and unpruned trees which can potentially be very large on some data sets. To reduce memory consumption, the complexity and size of the trees should be controlled by setting those parameter values. Thepredict()method operates using thenumpy.argmax()function on the outputs ofpredict_proba(). This means that in case the highest predicted probabilities are tied, the classifier will predict the tied class with the lowest index in classes_.- __init__(fuzziness=0.8, criterion='gini', max_depth=None, min_membership_split=2.0, min_membership_leaf=1.0, min_impurity_decrease=0.0)[source]¶
- fit(X, y, sample_weight=None, check_input=True)[source]¶
Build a fuzzy decision tree classifier from the training set (X, y).
- Parameters:
- Xarray-like of shape (n_samples, n_features)
The training input samples. Internally, it will be converted to
dtype=np.float64.- yarray-like of shape (n_samples,)
The target values (class labels) as integers or strings. Internally, it will be converted to an array-like of integers.
- sample_weightarray-like of shape (n_samples,), default=None
Sample weights used as initial membership function for samples. If None, then samples are equally weighted. Splits that would create child nodes with net zero membership are ignored while searching for a split in each node.
- check_inputbool, default=True
Allow to bypass several input checking. Don’t use this parameter unless you know what you do.
- Returns:
- selfFuzzyDecisionTreeClassifier
Fitted estimator.
- predict_log_proba(X, check_input=True)[source]¶
Predict class log-probabilities of the input samples X.
- Parameters:
- Xarray-like of shape (n_samples, n_features)
The input samples. Internally, it will be converted to
dtype=np.float64.- check_inputbool, default=True
Allow to bypass several input checking. Don’t use this parameter unless you know what you do.
- Returns:
- probandarray of shape (n_samples, n_classes)
The class log-probabilities of the input samples. The order of the classes corresponds to that in the attribute classes_.
- predict_proba(X, check_input=True)[source]¶
Predict class probabilities of the input samples X. The predicted class probability is the fraction of membership of samples of the same class in a leaf.
- Parameters:
- Xarray-like of shape (n_samples, n_features)
The input samples. Internally, it will be converted to
dtype=np.float64.- check_inputbool, default=True
Allow to bypass several input checking. Don’t use this parameter unless you know what you do.
- Returns:
- probandarray of shape (n_samples, n_classes)
The class probabilities of the input samples. The order of the classes corresponds to that in the attribute classes_.
- set_fit_request(*, check_input: bool | None | str = '$UNCHANGED$', sample_weight: bool | None | str = '$UNCHANGED$') FuzzyDecisionTreeClassifier¶
Request metadata passed to the
fitmethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed tofitif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it tofit.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
- check_inputstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
check_inputparameter infit.- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter infit.
- Returns:
- selfobject
The updated object.
- set_predict_log_proba_request(*, check_input: bool | None | str = '$UNCHANGED$') FuzzyDecisionTreeClassifier¶
Request metadata passed to the
predict_log_probamethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed topredict_log_probaif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it topredict_log_proba.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
- check_inputstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
check_inputparameter inpredict_log_proba.
- Returns:
- selfobject
The updated object.
- set_predict_proba_request(*, check_input: bool | None | str = '$UNCHANGED$') FuzzyDecisionTreeClassifier¶
Request metadata passed to the
predict_probamethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed topredict_probaif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it topredict_proba.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
- check_inputstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
check_inputparameter inpredict_proba.
- Returns:
- selfobject
The updated object.
- set_predict_request(*, check_input: bool | None | str = '$UNCHANGED$') FuzzyDecisionTreeClassifier¶
Request metadata passed to the
predictmethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed topredictif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it topredict.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
- check_inputstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
check_inputparameter inpredict.
- Returns:
- selfobject
The updated object.
- set_score_request(*, sample_weight: bool | None | str = '$UNCHANGED$') FuzzyDecisionTreeClassifier¶
Request metadata passed to the
scoremethod.Note that this method is only relevant if
enable_metadata_routing=True(seesklearn.set_config()). Please see User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toscoreif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toscore.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Note
This method is only relevant if this estimator is used as a sub-estimator of a meta-estimator, e.g. used inside a
Pipeline. Otherwise it has no effect.- Parameters:
- sample_weightstr, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED
Metadata routing for
sample_weightparameter inscore.
- Returns:
- selfobject
The updated object.
Examples using fuzzytree.FuzzyDecisionTreeClassifier¶
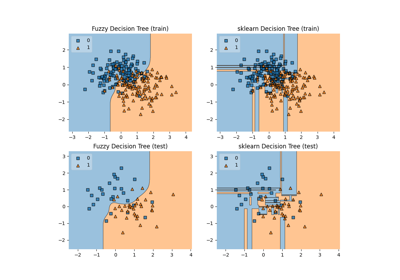
Comparison of crisp and fuzzy classifiers on make_moons dataset
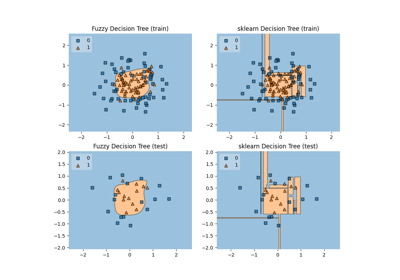
Comparison of crisp and fuzzy classifiers on make_circles dataset
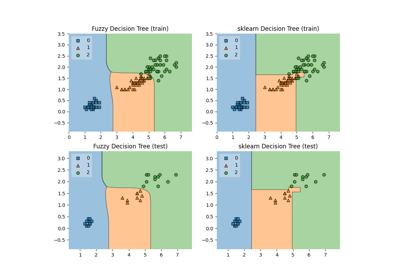
Comparison of crisp and fuzzy classifiers on iris dataset
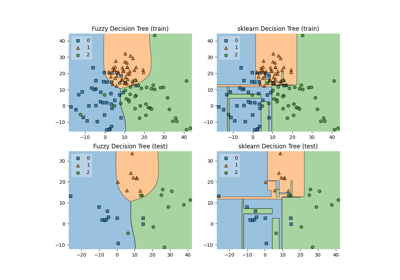
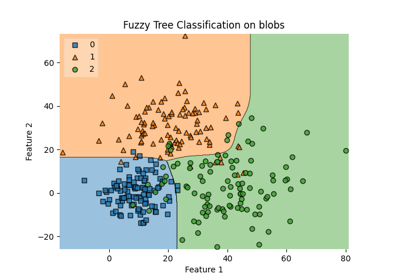
Comparison of crisp and fuzzy classifiers on make_blobs dataset